How I Wrote Papers in College
tldr; I hate MS Word with a passion, so I wrote a custom build system to convert a combination of Markdown and Latex into a PDF.
The Problem
At its core, Microsoft Office products are glorified XML editors, with the x standing for XML. (If you don't believe me, go and rename a .pptx or .docx to .zip and unzip it. This is also how you can retrieve the original image files from one of these formats.)
WYSIWYG (what you see is what you get) editors are great for a lot of things, but I believe that pure text driven formats are better for writing and editing as you can more clearly identify structure, styling, and content.
With this, I set out to build a system where I could leverage my knowledge of code to write better papers.
The Solution
Leveraging the following:
- VSCode
- Multi-pane viewing / editing
- A PDF viewer extension for hot reloading
- The Markdown All in One extension for formatting
- CoPilot (more on this later)
- Markdowns simplicity of syntax
- Latex's powerful typesetting
pandoc's ability to convert between formats- Some simple PowerShell scripting
- The
cspellcli for spell checking - The
--citeprocflag for appending BibTex citations and the citation-style-language repo for auto APA/MLA/Chicago formatting
pandoc --pdf-engine=lualatex $args[0] -o $args[1] --highlight-style tango --bibliography .\refs.bib --citeproc
# --pdf-engine=lualatex: use lualatex as the pdf engine
# $args[0]: the first argument passed to the script
# -o $args[1]: the second argument passed to the script
# --highlight-style tango: use the tango syntax highlighting style
# --bibliography .\refs.bib: use the refs.bib file as the bibliography
# --citeproc: append citationsI was able to easily turn:
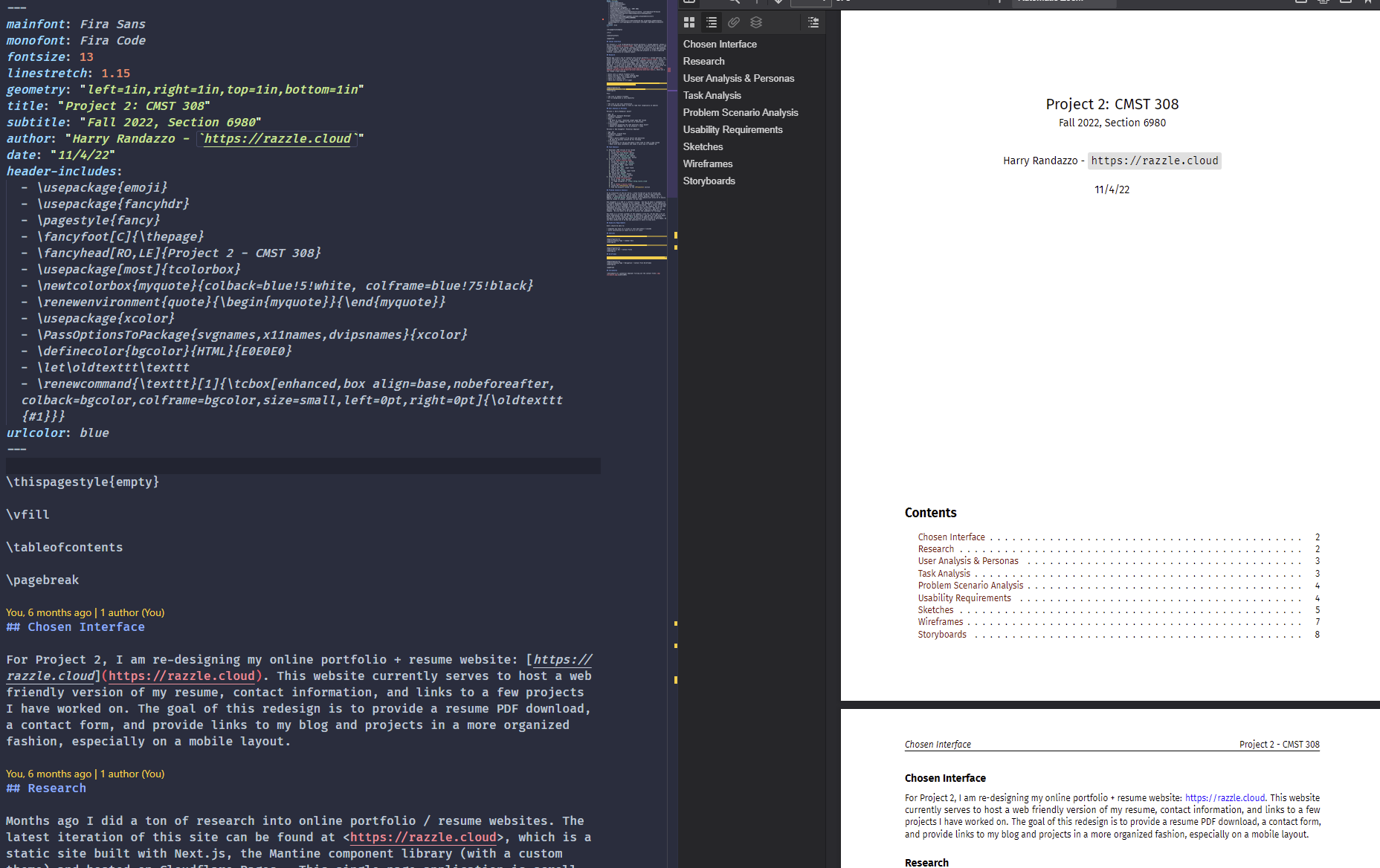
The
build.ps1 script$project = $args[0]
$projectName = $project + ".md"
$output = "dist/$project - Randazzo.pdf"
while ($true) {
$shaExists = Test-Path -Path .\sha.txt
if ($shaExists -ne $true) {
Write-Output "0000" | Out-File .\sha.txt
}
$oldSha = Get-Content .\sha.txt
$sha = Get-FileHash $projectName | Select-Object -ExpandProperty Hash
if ($sha -ne $oldSha) {
Clear-Host
Write-Host "File changed!" -ForegroundColor Cyan
$sha | Out-File .\sha.txt
Start-Job -Name Export -ArgumentList $projectName, $output -ScriptBlock {
cspell $args[0] --no-progress --show-suggestions --no-summary
$citationsExist = Test-Path -Path .\refs.bib
if ($citationsExist -ne $true) {
pandoc --pdf-engine=lualatex $args[0] -o $args[1] --highlight-style tango
}
else {
pandoc --pdf-engine=lualatex $args[0] -o $args[1] --highlight-style tango --bibliography .\refs.bib --citeproc
}
} | Out-Null
$e = Get-Job -Name Export
Clear-Host
$PSStyle.Progress.View = 'Classic'
while ($e.State -eq "Running") {
$rand = Get-Random -Minimum 1 -Maximum 100
Write-Progress -Activity "Exporting $projectName to PDF" -PercentComplete $rand
Start-Sleep -Milliseconds 250
}
Write-Progress -Activity "Exporting $projectName to PDF" -PercentComplete 100 -Completed
$e | Receive-Job -Keep | Out-Host
Remove-Job -Name Export -Force
$ts = Get-Date -Format 'HH:mm:ss'
Write-Host "[$ts] " -ForegroundColor Gray -NoNewline
Write-Host "✅ PDF '$output' @ $($sha[0..8] | Join-String)" -ForegroundColor Green
}
Start-Sleep -Milliseconds 1000
}
CoPilot
CoPilot is an AI powered code assistant that was trained on billions of lines of code. It's a VSCode extension that can autocomplete code for you. But, at its core, it is a text prediction engine that is going to continually provide the logic continuation of a thought or sentence. This is what makes it so powerful for writing.

In my essays, I could outline an entire paper with my thoughts, citations, and structure, and then leverage CoPilot to aid me in fleshing out the body and maintaining a coherent structure and flow of ideas. CoPilot has a tendency to repeat itself; replicating phrases, endings of paragraphs and entire sentences (it was trained to replicate and reduce the need for a human to write boilerplate code after all). But, it was still a very powerful tool that allowed me to focus more on what I was saying rather than on how to say it.
Layout
The simplicity of Markdown is near unmatched. It's a simple syntax that is easy to read and write, but it has a few shortcomings. For example, it is not designed to handle page layout (page breaks, margins, page numbers, etc.). This is where Latex comes in.
Latex is a typesetting language that is designed to handle page layout. It is a very powerful tool that can be used to create beautiful documents. It is also very verbose and difficult to read and write. By leveraging the pandoc cli, I was able to convert my Markdown into Latex and then into a PDF.
Since both Markdown and Latex are plaintext formats, I was able to use the cspell NodeJS cli to spell check my papers.
cspell $args[0] --no-progress --show-suggestions --no-summaryCitations
With the ability to leverage the entire Latex ecosystem, I was able to use the --citeproc flag to add citations to my papers. This allowed me to use a .bib file to store my citations and then reference them in my paper. (citationmachine.net eat your heart out)
# refs.bib
@article{ntma,
title = {Deep Learning for Network Traffic Monitoring and Analysis (NTMA): A Survey},
journal = {Computer Communications},
volume = {170},
pages = {19-41},
year = {2021},
issn = {0140-3664},
doi = {https://doi.org/10.1016/j.comcom.2021.01.021},
url = {https://www.sciencedirect.com/science/article/pii/S0140366421000426},
author = {Mahmoud Abbasi and Amin Shahraki and Amir Taherkordi},
keywords = {Network Traffic Monitoring and Analysis, Network management, Deep learning, Machine learning, Survey, NTMA, Edge Intelligence, IoT, QoS},
abstract = {Modern communication systems and networks, e.g., Internet of Things (IoT) and cellular networks, generate a massive and heterogeneous amount of traffic data. In such networks, the traditional network management techniques for monitoring and data analytics face some challenges and issues, e.g., accuracy, and effective processing of big data in a real-time fashion. Moreover, the pattern of network traffic, especially in cellular networks, shows very complex behavior because of various factors, such as device mobility and network heterogeneity. Deep learning has been efficiently employed to facilitate analytics and knowledge discovery in big data systems to recognize hidden and complex patterns. Motivated by these successes, researchers in the field of networking apply deep learning models for Network Traffic Monitoring and Analysis (NTMA) applications, e.g., traffic classification and prediction. This paper provides a comprehensive review on applications of deep learning in NTMA. We first provide fundamental background relevant to our review. Then, we give an insight into the confluence of deep learning and NTMA, and review deep learning techniques proposed for NTMA applications. Finally, we discuss key challenges, open issues, and future research directions for using deep learning in NTMA applications.}
}
"Although different NTMA techniques ..." [@ntma]
\pagebreak
## Sourceswould become


Conclusion
It wasn't easy setting up the initial build system, as these tools were not fully designed to work 100% well together, but the end product is an amazing tool that carried me through countless papers, reports, and essays. By defining a nice baseline format, then extending it as needed per-project, I was able to create a very powerful and flexible system that allowed me to focus on the content of my papers rather than the formatting.
Don't worry, I hate PowerPoint just as much as Word, and used reveal.js to create my presentations. But that's a story for another time. https://noxsios.github.io/ctf-slides/
Now you may be wondering, why go through all this trouble? Surely something already exists that fulfills this need? Until two months ago you would be wrong; as there is now a very powerful open source cli called typst that aims to perform this very task. The syntax is a combination of Markdown and a custom AST that looks to be really powerful. I'm excited to see where it goes.